
In today’s rapidly evolving tech landscape, Site Reliability Engineering (SRE) has become one of the most in-demand roles across industries. As organizations scale and systems become more complex, the need for professionals who can bridge the gap between development and operations is critical. If you’re looking to start or transition into a career in SRE, this comprehensive SRE roadmap will guide you step by step in 2025.
Why Follow an SRE Roadmap?
The field of SRE is broad, encompassing skills from DevOps, software engineering, cloud computing, and system administration. A well-structured SRE roadmap helps you:
Understand the essential skills required at each stage.
Avoid wasting time on non-relevant tools or technologies.
Stay up to date with industry standards and best practices.
Get job-ready with the right certifications and hands-on experience.
SRE Roadmap: Step-by-Step Guide
🔹 Phase 1: Foundation (Beginner Level)
Key Focus Areas:
Linux Fundamentals – Learn the command line, shell scripting, and process management.
Networking Basics – Understand DNS, HTTP/HTTPS, TCP/IP, firewalls, and load balancing.
Version Control – Master Git and GitHub for collaboration.
Programming Languages – Start with Python or Go for scripting and automation tasks.
Tools to Learn:
Git
Visual Studio Code
Postman (for APIs)
Recommended Resources:
"The Linux Command Line" by William Shotts
GitHub Learning Lab
🔹 Phase 2: Core SRE Skills (Intermediate Level)
Key Focus Areas:
Configuration Management – Learn tools like Ansible, Puppet, or Chef.
Containers & Orchestration – Understand Docker and Kubernetes.
CI/CD Pipelines – Use Jenkins, GitLab CI, or GitHub Actions.
Monitoring & Logging – Get familiar with Prometheus, Grafana, ELK Stack, or Datadog.
Cloud Platforms – Gain hands-on experience with AWS, GCP, or Azure.
Certifications to Consider:
AWS Certified SysOps Administrator
Certified Kubernetes Administrator (CKA)
Google Cloud Professional SRE
🔹 Phase 3: Advanced Practices (Expert Level)
Key Focus Areas:
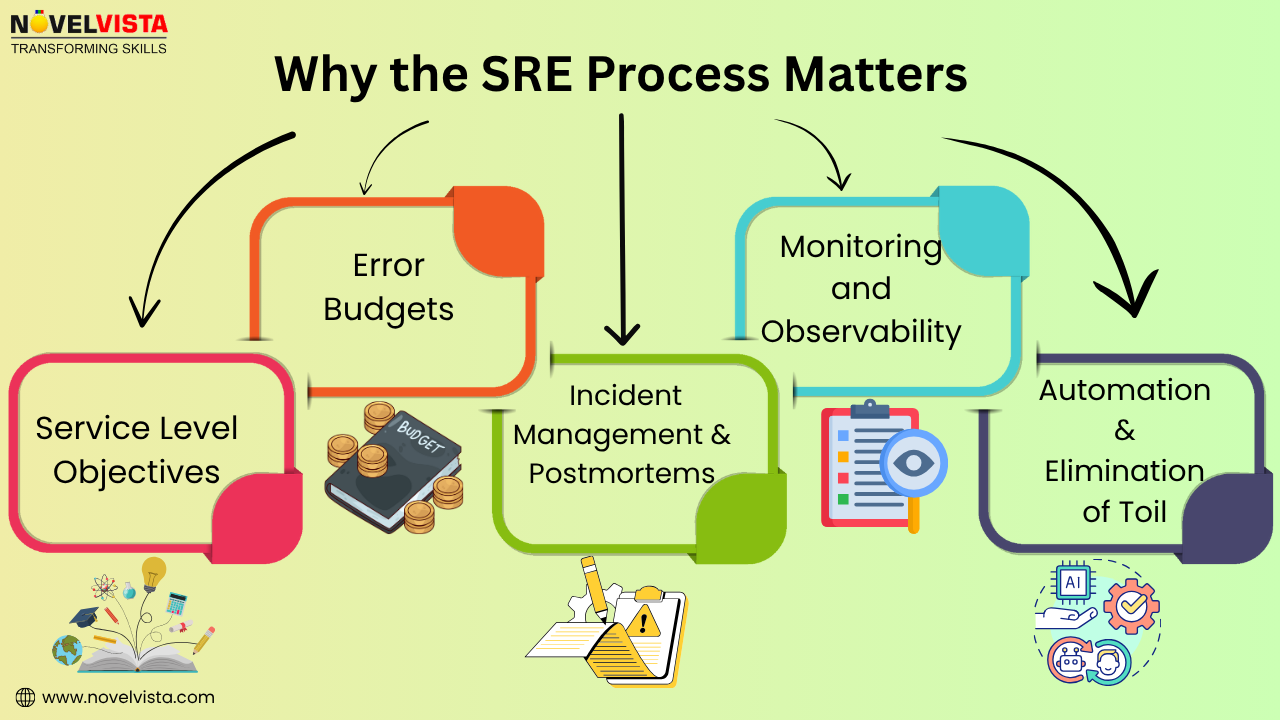
Site Reliability Principles – Learn about SLIs, SLOs, SLAs, and Error Budgets.
Incident Management – Practice runbooks, on-call rotations, and postmortems.
Infrastructure as Code (IaC) – Master Terraform or Pulumi.
Scalability and Resilience Engineering – Understand fault tolerance, redundancy, and chaos engineering.
Tools to Explore:
Terraform
Chaos Monkey (for chaos testing)
PagerDuty / OpsGenie
Real-World Experience Matters
While theory is important, hands-on experience is what truly sets you apart. Here are some tips:
Set up your own Kubernetes cluster.
Contribute to open-source SRE tools.
Create a portfolio of automation scripts and dashboards.
Simulate incidents to test your monitoring setup.
Final Thoughts
Following this SRE roadmap will provide you with a clear and structured path to break into or grow in the field of Site Reliability Engineering. With the right mix of foundational skills, real-world projects, and continuous learning, you'll be ready to take on the challenges of building reliable, scalable systems.
Ready to Get Certified?
Take your next step with our SRE Certification Course and fast-track your career with expert training, real-world projects, and globally recognized credentials.



















Write a comment ...